Avaliamos o desempenho do LLaMA e do Qwen em tarefas de inferência textual voltadas ao setor público. Os resultados mostraram a importância da comparação entre modelos de IA em domínios críticos como saúde, educação e segurança.

Por que devemos comparar modelos de IA generativas em contextos especializados?
Nem todo modelo generalista funciona bem em contextos especializados (ex: Administração pública, jurídico, saúde e etc..). O benchmarking nos permite avaliar a capacidade do modelo em lidar com vocabulário técnico, contexto semântico e estilo textual específicos. Através de testes comparativos, podemos detectar alucinações, vieses, erros de inferência ou fragilidade em tarefas críticas.
Para que essa comparação seja significativa, precisamos construir cenários de avaliação que simulam tarefas reais encontradas nos domínios especializados. Isso envolve a elaboração de entradas formuladas, com base em documentos, legislações, ou situações práticas, permitindo observar como os modelos respondem diante desses casos.
Com o objetivo de realizar um estudo comparativo entre os LLMs (Large Language Models ), definimos algumas métricas-chave para avaliar o desempenho desses modelos dentro de um contexto especializado.
Taxa de compreensão contextual
A primeira métrica avaliada foi a de compreensão textual, na qual aplicamos técnicas de Inferência de Linguagem Natural (NLI). Por meio desse método, quantificamos a capacidade dos modelos de compreender textos no contexto governamental. Para isso, foram analisadas frases compostas por uma premissa e uma hipótese, desafiando os modelos a classificar a relação entre elas como implicação, contradição ou neutralidade.
Exemplo da estruturação das sentenças definidas em cinco níveis de dificuldade: Muito Fácil, Fácil, Médio, Difícil ou Muito Difícil :
[
{
"categoria": "Segurança Pública",
"premissa": "O policiamento ostensivo foi aumentado no bairro.",
"hipotese": "A presença de policiais nas ruas do bairro diminuiu.",
"nivel": "Muito Fácil",
"gabarito": "Contradição"
},
{
"categoria": "Saúde",
"premissa": "A vacinação em massa contra a poliomielite foi realizada.",
"hipotese": "A campanha de imunização contra a paralisia infantil aconteceu.",
"nivel": "Muito Fácil",
"gabarito": "Implicação"
}
]Executando o Teste e Coletando Dados
Todos os modelos testados receberam as mesmas instruções para classificar, em uma única palavra, a relação entre premissa e hipótese. Foram registradas todas as respostas juntamente com logs detalhados de cada interação, registro de anomalias e comportamentos não previstos. Para execução do teste foi implementada uma pipeline de compreensão textual com LangChain e NLI. Estruturado da seguinte forma:
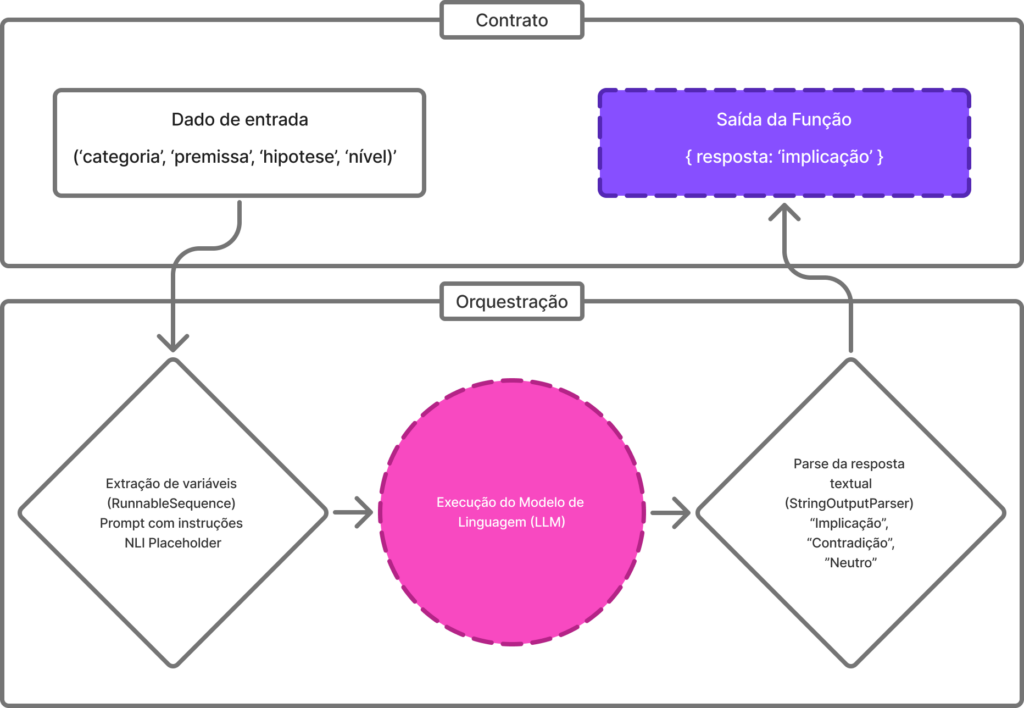
1- Contrato de entrada
Esta etapa define os dados esperados pela função compreensaoTextual
A função de cada campo:
- categoria: saúde, educação, infraestrutura, segurança e administração pública.
- premissa: Sentença base que contém os fatos.
- hipotese: Afirmação que será analisada com base na premissa.
- nivel: Indica a dificuldade da inferência.
2- Extração de Variáveis + Prompt Dinâmico
RunnableSequence é uma estrutura do LangChain que encadeia múltiplas etapas de execução como (input → prompt → modelo → parser). Funciona como um pipeline modular e reativo. Cada etapa recebe a saída da anterior.
As etapas:
- O RunnableSequence extrai os dados do ctx.
- Esses dados são inseridos no prompt por meio de placeholders como {premissa} e {hipotese}.
- O prompt é construído dinamicamente com ChatPromptTemplate.fromMessages().
3- Execução do Modelo de Linguagem (LLM)
O LangChain envia o prompt para um modelo de linguagem selecionado dinamicamente de acordo com o provedor informado.
As etapas do LLM:
- Leitura da premissa.
- Análise da hipótese.
- Classificação lógica da relação
4- Parse da Resposta Textual
Nessa fase é feita a interpretação e estruturação da saída bruta do modelo. O tratamento é feito através da ferramenta StringOutputParser encontrado no LangChain. Esse tratamento da saída remove os espaços em branco, quebras de linha, ou textos desnecessários.
5- Saída da Função
Com intuito de salvar as respostas dos testes para o benchmarking entre modelos. A saída da função é estruturada é dada por: { resposta: “implicação” }
Resultados preliminares
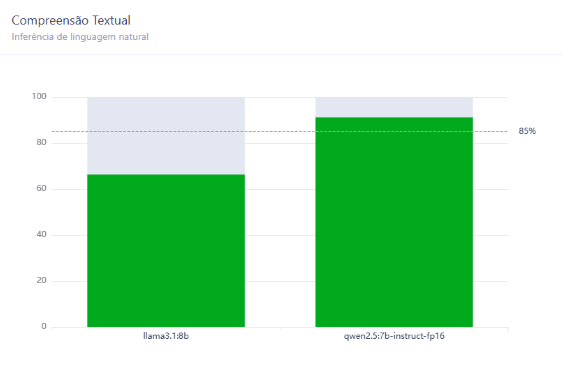
Inicialmente, foram testados os modelos LLaMA 3.1:8B e Qwen 2.5:7B. No contexto governamental, com segmentações nas áreas de saúde, educação, infraestrutura, segurança e administração pública, o modelo Qwen apresentou um desempenho superior, acertando 90% das questões. Já o modelo LLaMA teve um desempenho abaixo do esperado, com uma taxa de acerto em torno de 65%.
Um ponto relevante sobre o desempenho do LLaMA é que, embora em alguns casos as respostas estivessem corretas, o modelo não seguiu as instruções do prompt, que exigiam respostas diretas classificadas como “Implicação”, “Contradição” ou “Neutro”. Em vez disso, o modelo frequentemente incluiu justificativas junto à resposta, o que comprometeu a avaliação automatizada.
Próximos passos
Em breve, iremos avaliar diversos modelos e parâmetros com o objetivo de tornar o benchmarking mais abrangente. Também realizaremos análises com base em outras métricas, tais como: clareza da resposta, tempo médio de resposta, tratamento de ambiguidade e etc. Todas essas avaliações ocorrerão no âmbito governamental , garantindo que os resultados sejam aplicáveis a contextos reais de gestão pública.
Gostei bastante
Muito objetivo o artigo.
Ótimo artigo!