Nos últimos anos, a transparência pública tem se tornado cada vez mais importante. O portal da transparência do governo disponibiliza informações valiosas sobre emendas parlamentares, mas a forma como esses dados são apresentados nem sempre facilita o acesso do cidadão comum. Foi nesse contexto que nasceu este projeto: criar um Agente de Inteligência Artificial que pudesse responder a perguntas em linguagem natural sobre emendas parlamentares.
O diferencial foi utilizar o Google ADK com um servidor MCP local para orquestrar ferramentas de busca sobre um arquivo Excel baixado diretamente do portal da transparência. Assim, o usuário poderia perguntar de maneira natural, e o agente interpretaria a solicitação, filtrando os dados de forma automática.
1. Primeira abordagem: ferramenta única de busca por filtros
Na primeira versão, criei a ferramenta chamada buscar_emendas.
A ideia era simples: o usuário faria a pergunta em português e, dentro da função, um LLM (Large Language Model) interpretaria o texto, transformando-o em um filtro estruturado.
Por exemplo:
Pergunta do usuário:
Liste as emendas cujo beneficiário é “Associação dos Agricultores de Goiás” e que tiveram valor liquidado acima de 100000 em 2022.
Filtro esperado:
{
"Ano Emenda": "2022",
"Beneficiário": "Associação dos Agricultores de Goiás",
"Valor Liquidado (R$)": ">100000"
}Essa solução funcionava bem para consultas diretas de filtragem.
Limitações encontradas:
Apesar de útil, essa abordagem tinha um problema estrutural: ela só atendia a perguntas que pudessem ser transformadas em filtros diretos.
Por exemplo:
Pergunta do usuário::
Qual o valor total das emendas previstas do Deputado Qualquer em 2024?
Esse tipo de questão não é apenas um filtro, mas uma agregação numérica. Ou seja, não bastava retornar linhas da planilha, era preciso somar valores.
Essa limitação mostrou que eu precisaria de algo mais flexível.
Expansão para múltiplas funções:
Diante disso, criei cinco funções diferentes, cada uma cobrindo um tipo de pergunta:
- buscar_filtros – consultas simples por filtros.
- agregação_numerica – cálculos como soma, média, mínimo e máximo.
- ranking_ordenacao – perguntas do tipo “quem são os maiores beneficiários”.
- estatisticas_coluna – estatísticas gerais sobre uma coluna (quantidade, valores distintos etc.).
- busca_texto – buscas por palavras ou expressões em campos de texto.
Com isso, o agente passou a decidir sozinho qual ferramenta usar de acordo com a pergunta.
Essa evolução funcionou, mas a complexidade aumentou muito. Cada ferramenta exigia tratamento específico, e a manutenção ficava cada vez mais difícil.
2. Segunda abordagem: Repensando a arquitetura para SQL como linguagem universal
Foi então que decidimos recomeçar o projeto com outra abordagem.
Em vez de manter várias ferramentas, a ideia passou a ser ter uma única ferramenta de busca, capaz de converter a pergunta do usuário diretamente em uma consulta SQL.
O fluxo ficou assim:
- O usuário faz a pergunta em linguagem natural.
- O LLM interpreta a pergunta e gera uma query SQL.
- Essa query é executada no DataFrame com os dados das emendas.
- O resultado é devolvido ao agente, que responde ao usuário.
Dessa forma, perguntas simples ou complexas são tratadas da mesma maneira.
Exemplo:
Pergunta:
Qual o valor total das emendas previstas do Deputado Qualquer em 2024?
SQL gerado:
SELECT SUM("Valor Previsto (R$)")
FROM emendas<br>WHERE "Autor da Emenda" = 'Deputado Qualquer'
AND "Ano Emenda" = 2024;Essa mudança simplificou bastante o projeto e trouxe muito mais poder de consulta, já que o SQL é naturalmente expressivo e cobre uma ampla gama de perguntas possíveis.
O desafio da performance e a solução final:
Apesar do ganho em flexibilidade com SQL, surgiu um novo problema: consultas muito complexas exigiam que o modelo usado até então, o gpt-oss:20b, entrasse em modo thinking. Esse processo permitia ao modelo raciocinar em múltiplos passos e criar SQLs complexos, mas trazia um custo: as respostas ficavam muito lentas.
Esse modelo tinha as seguintes características:
- Nome: gpt-oss:20b
- Capacidades: suporta ferramentas e thinking
- Tamanho: ~14GB
- Janela de contexto: 128K tokens
Para consultas simples e frequentes, esse comportamento era um gargalo de performance.
A solução foi dividir as buscas em dois níveis, utilizando também um segundo modelo: qwen2.5:14b, que não possui modo thinking. Ele é mais rápido e adequado para consultas diretas. Suas especificações são:
- Nome: qwen2.5:14b
- Capacidades: suporta ferramentas, mas sem thinking
- Tamanho: ~9GB
- Janela de contexto: 32K tokens
Assim, a arquitetura final ficou organizada em duas ferramentas:
- busca_simples_emenda – roda no qwen2.5:14b, que responde rápido e cobre a maior parte das perguntas usuais.

- busca_avancada_emenda – roda no gpt-oss:20b, que entra em modo thinking apenas quando necessário para consultas complexas.
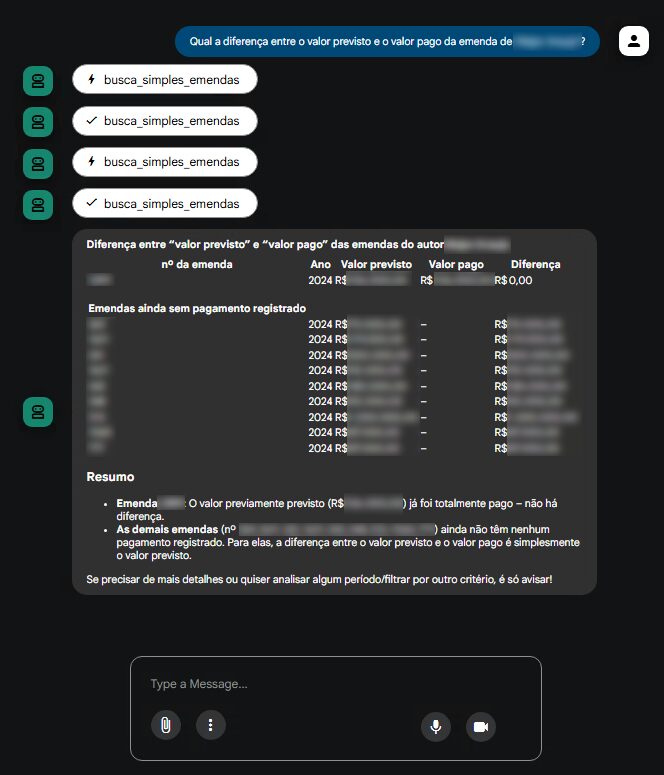
O agente passou a ter uma estratégia adaptativa:
- Primeiro tenta resolver com o modelo simples (qwen2.5:14b).
- Se a resposta não for suficiente, escala para o modelo avançado (gpt-oss:20b).
Esse arranjo trouxe o equilíbrio ideal entre velocidade e capacidade de raciocínio complexo, garantindo boa experiência para o usuário sem abrir mão de consultas sofisticadas.
3. Conclusão
O projeto passou por diversas fases de evolução:
- Filtros simples → bom início, mas limitado.
- Conjunto de funções especializadas → mais flexível, porém complexo demais.
- SQL como linguagem de consultas → solução enxuta e poderosa.
- Divisão entre busca simples e avançada → equilíbrio entre rapidez e capacidade de lidar com complexidade.
Esse caminho mostra bem os desafios de construir um agente de IA: não basta apenas usar um LLM, é preciso iterar, testar, identificar gargalos e redesenhar a arquitetura até encontrar um ponto de equilíbrio.
No fim, o agente se tornou capaz de responder a perguntas em linguagem natural sobre emendas parlamentares de maneira eficiente, robusta e escalável, unindo simplicidade de uso e poder analítico.