Concordância entre modelos de linguagem na avaliação da clareza das respostas

Testamos os modelos LLaMA e Qwen para pontuar a concordância na clareza de textos relacionados a saúde, educação e segurança.
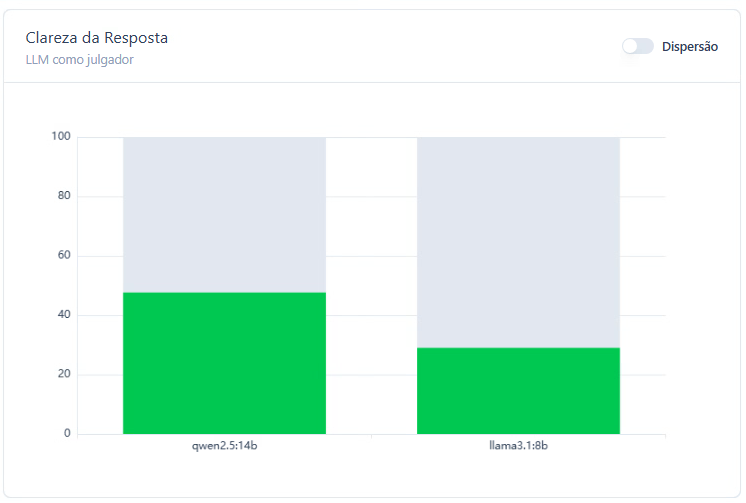
Taxa Concordância na Resposta
A métrica concordância das respostas, utilizamos modelos de linguagem (LLMs) como juízes para pontuar o quão claro era o conteúdo apresentado. Os textos avaliados pertencem ao contexto governamental, abrangendo os temas de saúde, educação e segurança pública. Para essa avaliação, os modelos receberam um conjunto de critérios: objetividade, linguagem simples, ausência de ambiguidade e adequação ao contexto. Cada resposta foi pontuada em uma escala de 1 a 5, sendo:
- 1: nada claro
- 5: perfeitamente claro
[{"texto": "Foram pavimentados 14 km na região norte, conforme relatório técnico nº 009/2024.","gabarito": 5},{"texto": "A iluminação pública está sendo cuidada, mas sem mais detalhes.","gabarito": 1},{"texto": "O bairro Novo Horizonte conta com rondas diárias da Polícia Militar.","gabarito": 4}]
Executando o Teste e Coletando Dados
Todos os modelos testados receberam as mesmas instruções para pontuar a clareza da sentença informada. Foram registradas todas as respostas juntamente com logs detalhados de cada interação e com registro de anomalias e comportamentos não previstos. Para execução do teste foi usada a estrutura LangChain.
Avaliamos a concordância das respostas com LLMs
Para medir a concordância das respostas, desenvolvemos uma estrutura programática baseada na biblioteca LangChain, que permite orquestrar interações com modelos de linguagem (LLMs). Abaixo, explicamos passo a passo como essa avaliação foi conduzida:
Definição da tarefa: Cada modelo recebeu a tarefa de avaliar o quão clara era uma resposta textual, utilizando uma escala Likert de 1 a 5.
A clareza foi definida com base nos critérios: objetividade, linguagem simples, ausência de ambiguidade e adequação ao contexto
Construção do prompt: Criamos um prompt fixo (do tipo system message) que instruiu o modelo a avaliar a clareza da resposta fornecida, sem apresentar justificativas — apenas retornando um número de 1 a 5.
Exemplo da instrução usada:
“Dada a seguinte resposta, avalie considerando a escala Likert, de 1 a 5 o quão clara ela é […] Responda apenas com um número de 1 a 5.”
Pipeline de execução (cadeia de tarefas)
Com a ajuda da RunnableSequence, organizamos a sequência de etapas:
- A entrada do usuário (o texto a ser avaliado) é recebida.
- O prompt é preenchido com esse texto.
- O modelo de linguagem é acionado com o prompt.
- A resposta do modelo (um número de 1 a 5) é extraída como string para ser usada nos resultados.
Execução da avaliação
Com essa estrutura, vários textos foram avaliados por diferentes modelos (como LLaMA e Qwen). Cada modelo agiu como um “juiz virtual”, atribuindo uma pontuação para a clareza da resposta sem interferência humana.
Resultados preliminares
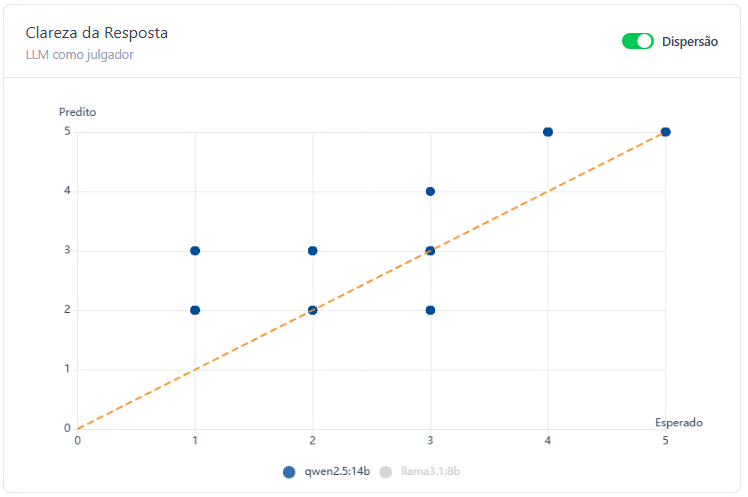
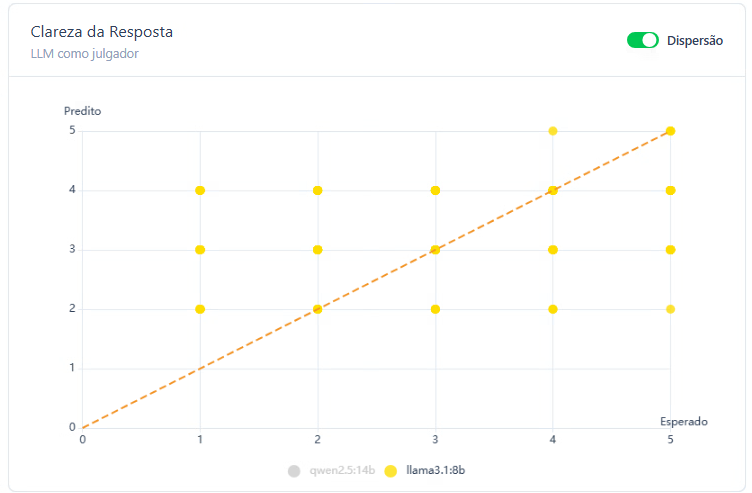
Inicialmente, foram testados os modelos LLaMA 3.1:8B e Qwen 2.5:7B. No contexto governamental, com segmentações nas áreas de saúde, educação, infraestrutura, segurança e administração pública. O modelo Qwen classificou corretamente 45% das respostas, demonstrando uma performance moderada na identificação de textos claros ou pouco claros conforme os critérios estabelecidos. O LLaMA, por sua vez, obteve um índice de acerto de 30%, indicando maior dificuldade em alinhar suas classificações ao gabarito humano de clareza. Esses resultados sugerem que, embora ambos os modelos apresentem potencial para tarefas de avaliação subjetiva, como a análise de clareza, o Qwen se mostrou mais alinhado às percepções humanas neste estágio preliminar do experimento.