
Nesse pequeno tutorial demonstrar-se-á o procedimento para copia de dados de tabelas de um BD relacional para a estrutura de dados do ambiente de Big Data Cloudera.
Esta tarefa será realizada com a utilização do PySpark via JupyterNotebook disponível na suíte do Big Data da Supadia/SGG.
É necessário ter acesso ao Jupyter Notebook do Big Data. O mesmo encontra-se no endereço abaixo:
https://jupyter.bigdata.go.gov.br/jupyter
Para a realização da tarefa o usuário deverá estar logado no ambiente.
1 – Configuração do ambiente para a correta conexão com o Cloudera.
Na tela inicial do Jupyter escolher a opção Notebook->Python 3(ipykernel)
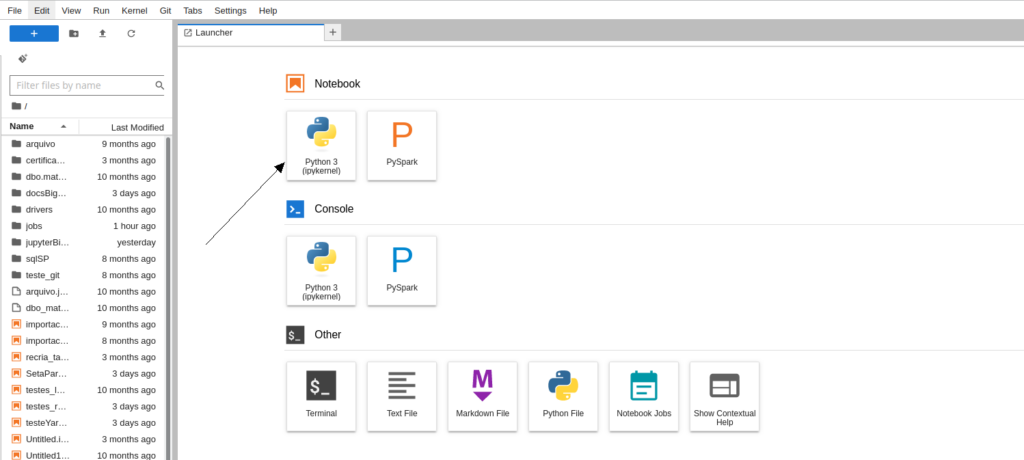
Após clicar no ícone anterior será aberta uma nova Aba com um notebook em branco:

Colar o código abaixo na célula editável
# Início do código (cortar e colar o código abaixo)
---- (Corte aqui)----
import base64
import json
# Preencher suas credenciais abaixo
usuario = "meu.usuario" (usuario do AD o mesmo do email @goias)
senha = "minha@senha" (senha do AD a mesma do email @goias)
configJson = {
"session_configs": {
"conf": {
"spark.yarn.queue": "default"
}
},
"livy_session_startup_timeout_seconds": 3600,
"should_heartbeat": True,
"livy_server_heartbeat_timeout_seconds": 0,
"heartbeat_refresh_seconds": 5,
"heartbeat_retry_seconds": 1,
"ignore_ssl_errors": True,
"retry_policy": "configurable",
"retry_seconds_to_sleep_list": [0.2, 0.5, 1, 3, 5],
"configurable_retry_policy_max_retries": 8,
"spark.yarn.queue": "developers",
"kernel_python_credentials": {
"username": "",
"base64_password": "",
"url": "https://cdpprodedgenode01.intra.goias.gov.br:8443/gateway/cdp-proxy-api/livy",
"auth": "Basic_Access"
},
"custom_headers": {
"X-Requested-By": "jupyter-hub"
}
}
configJson["kernel_python_credentials"]["username"] = usuario
configJson["kernel_python_credentials"]["base64_password"] = base64.b64encode(senha.encode()).decode('utf-8')
with open('.sparkmagic/config.json', 'w') as f:
json.dump(configJson, f)
---- (Corte aqui)----Após colar o código a tela ficará semelhante a seguir:

Executar o código colado acima utilizando o botão (ou utilizando Shift+Enter)

poś a execução será criado o arquivo “.sparkmagic/config.json” no seu home
Se nenhum erro ocorreu o ambiente está apto a conectar e criar sessões Spark no Cloudera.
2 – Criação de uma sessão Spark no Hadoop
Na tela inicial do Jupyter criar um novo “Launcher”. Isso pode ser feito no menu File->New Launcher,, ou com o botão “+” no topo esquerdo da janela logo abaixo do Menu principal,
ou pode ser aberto diretamente pela combinação de teclas Ctrl+Shift+L.
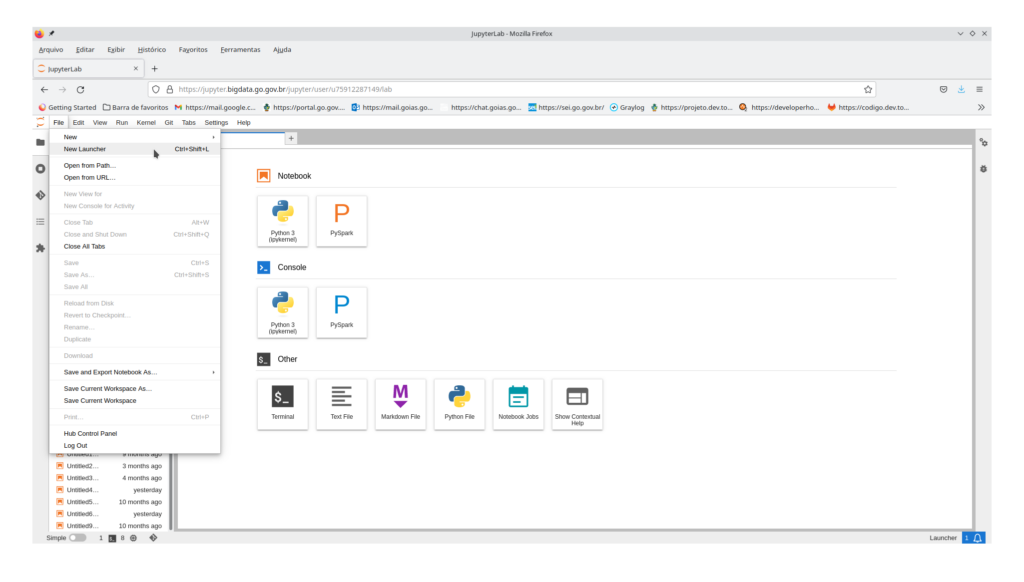
ou

Uma nova Aba será aberta como a seguir:
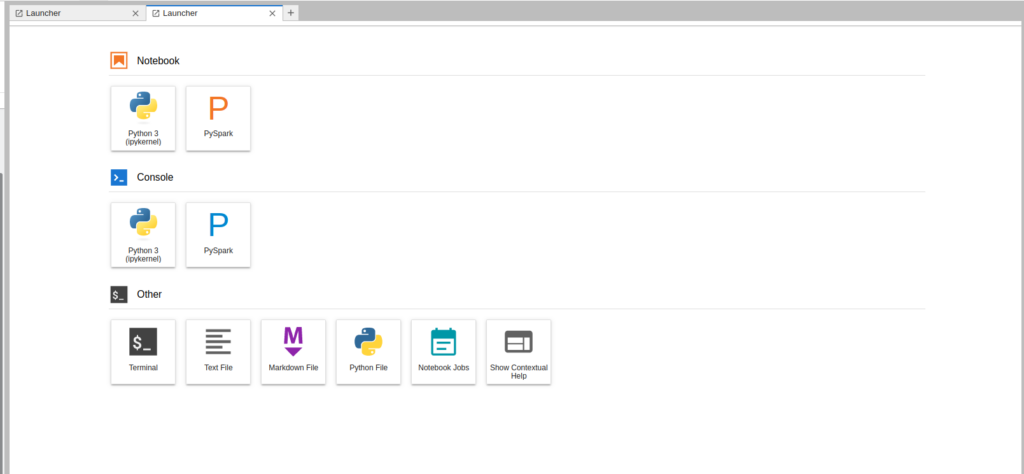
Criar um novo notebook PySpark. Para isso, selecionar “PySpark” na seção “Notebook” do Launcher (criado no passo anterior) como mostrado abaixo:
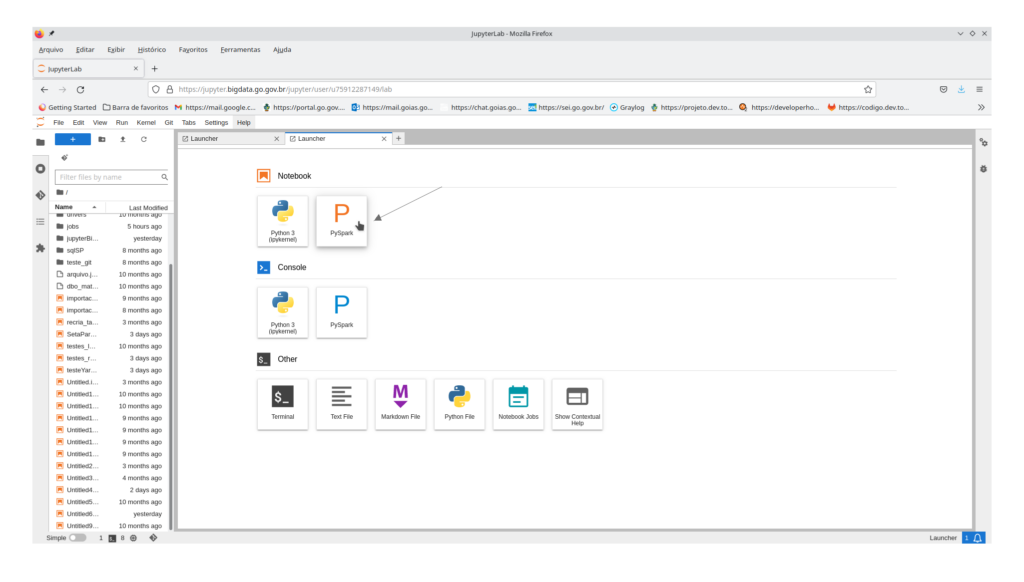
Será exibida uma nova aba com um notebook PySpark como mostrado abaixo:
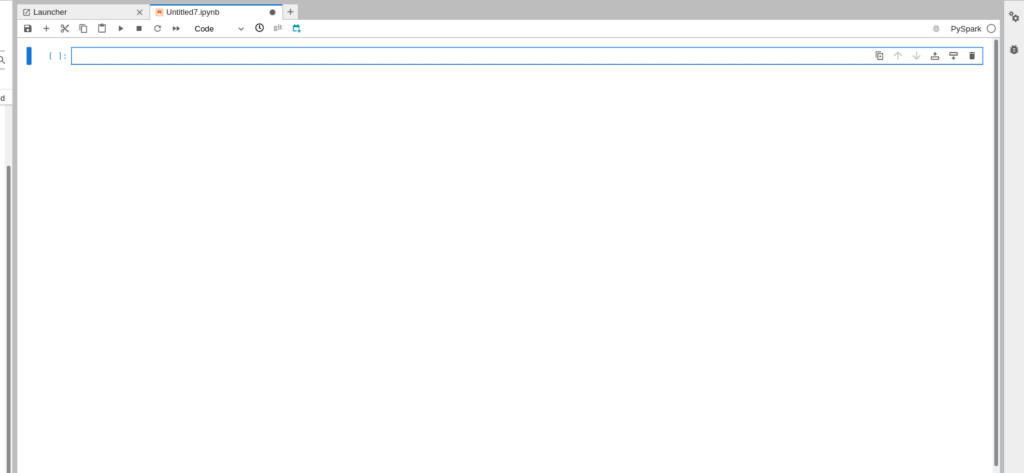
No campo editável, digitar (ou copiar e colar) o código abaixo para criar uma sessão Spark:
scApós a inclusão do código acima a tela deverá ser semelhante a mostrada a seguir:

Executar o código anterior. Utilizar o botão como mostrado a seguir (ou usar a combinação de teclas Shift+Enter com a célula em questão selecionada):

Aguardar alguns instantes. Uma nova sessão será criada no servidor. Será exibida uma mensagem semelhante à seguinte:
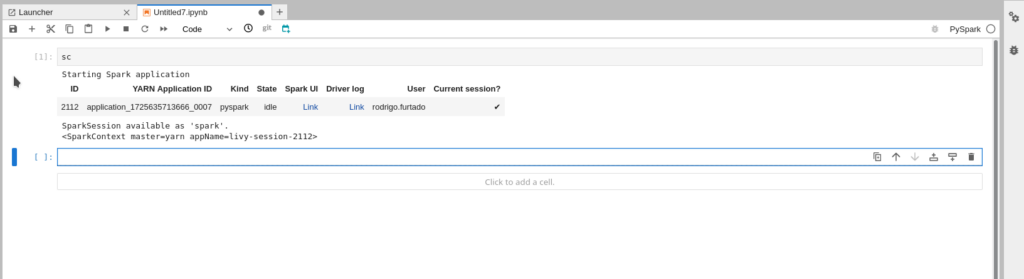
3 – Copiar uma tabela do seu BD relacional
Após o passo 2 na mesma tela em que foi criada a sessão Spark, copiar e colar o código abaixo na próxima linha editável (se não houver nenhuma célula acrescentar. Utilizar o botão “+” como mostrado na figura seguinte):
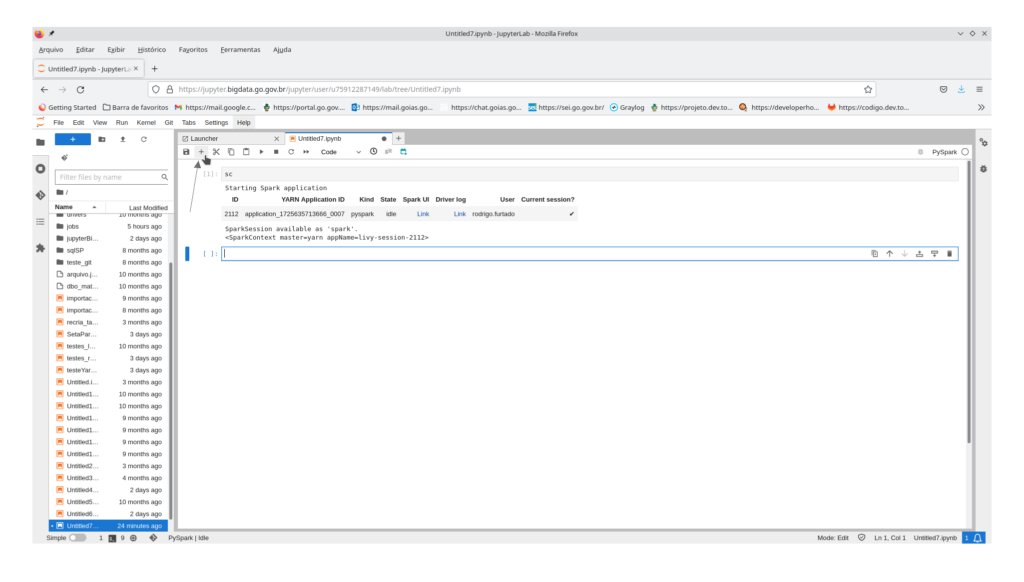
Copiar e colar o código seguinte:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:banco_de_dados://ip_ou_dns_do_servidor:porta_do_servidor;trustServerCertificate=true;databaseName=nome_do_banco_de_dados") \
.option("user", "usuario do seu banco") \
.option("password", "senha do seu BD") \
.option("driver", "jdbc_driver_do_seu_banco") \
.option("dbtable", "esquema.nome_da_tabela") \
.load()
jdbcDF.show(5)
jdbcDF.write.mode("overwrite").saveAsTable("esquema.nome_da_tabela")Detalhamento do código acima que deverá ser adaptado ao ambiente de BD relacional de onde deseja-se copiar as tabelas.
Na primeira linha executa-se a importação da lib necessária para que se possa ler da base de dados relacional e escrever no cloudera.
Na segunda linha cria-se uma variável com uma instância de sessão Spark (já instanciada na primeira linha de código) a qual será o objeto com as funções necessárias para realizar a tarefa de cópia.
Caso não haja sessão ela será criada com o comando .getOrCreate()
Os parâmetros das linhas da função read da variável spark:
.format("jdbc") - indica o formato da fonte de dados , no caso em questão é o jdbc.
.option("url", .....) - indica a url/string JDBC de conexão que será utilizada
Os parâmetros da url são:
banco_de_dados - é o nome do SGBD (sistema gerenciador de banco de dados) em questão. Ex.: mysql, postgresql, sqlserver, oracle, db2, etc...
ip_ou_dns_do_servidor - é o endereço ou nome do servidor de banco de dados. Ex.: localhost, 10.6.32.19, meuservidor.org, etc...
porta_do_servidor - é a porta utilizada para as conexões com o banco de dados. Ex.: 5432 (porta padrão do postgresql), 1433 (porta padrão do sqlserver), 3306 (porta padrão do mysql), 1521 (porta padrão do oracle) , 50000 (porta padrão do DB2), etc...
trustServerCertificate - é um parametro opcional caso utilize-se um sevidor de banco de dados com certificado autoassinado. Incluir essa opção com o valor booleano true para confiar no certificado: trustServerCertificate=true
databaseName - é o nome do banco de dados de onde será feita a cópia da tabela.
Continuando a descrição dos parâmetros:
.option("user", "...") - indica o nome de usuario de conexão com o banco de dados. Ex. root, joao.silveira, maria, etc...
.option("password", "...") - indica a senha do usuário de conexão com o banco de dados.
.option("driver", "...") - indica a classe de driver JDBC do banco de dados. Ex.: org.postgresql.Driver(postgesql), com.microsoft.sqlserver.jdbc.SQLServerDriver(sqlserver), org.mariadb.jdbc.Driver (mysql/MariaDB), oracle.jdbc.driver.OracleDriver (oracle), com.ibm.db2.jcc.DB2Driver(DB2), etc...
.option("dbtable", "...") - indica o nome do banco no SGBD onde encontra-se a(s) tabela(s) a serem copiada(s). Ex.: meuBanco, etc...
.load() - carrega as opções para o leitor de dados da sessão spark.
.show(5) - exibe as 5 primeiras linhas da tabela em questão
.write.mode("overwrite").saveAsTable("esquema.nome_da_tabela") - realiza a escrita da tabela no BigData
A opção "overwrite" indica que qualquer tabela/arquivo anterior com mesmo nome será sobrescrito. Ao utilizar este modo de gravação, o Spark excluirá o arquivo existente ou deletará a tabela existente no Bigdata antes de gravar a nova cópia.
.saveAsTable("esquema.nome_da_tabela") - indica o nome da tabela que será gravada no Big Data;
Mais opções de escrita podem se encontradas na referência abaixo :
https://sparkbyexamples.com/spark/spark-write-modes-explained/
A seguir encontra-se um exemplo de acesso a um banco de dados MS-SqlServer :
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:sqlserver://10.206.122.31:2733;trustServerCertificate=true;databaseName=sigeon") \
.option("user", "rodrigo.furtado") \
.option("password", "XXXXXX") \
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver") \
.option("dbtable", "dbo.PAP_uf") \
.load()
jdbcDF.show(5)
jdbcDF.write.mode("overwrite").saveAsTable("sbx_ligo.PAP_uf")Apoś configurar corretamente os parâmetros do código anterior de acordo com o ambiente de onde deseja-se copiar as tabelas, executar o mesmo (Shift+Enter). Se nenhum erro ocorrer haverá um retorno semelhante a figura a seguir:

Pronto, a importação da tabela para a estrutura do Big Data foi realizada.
